Ensemble Learning: Bagging, Boosting, Stacking
One powerful technique in machine learning which significantly enhances model performance is ensemble learning. In this blog, we’ll explore ensemble learning in detail, including what it is, how to use it, when it’s appropriate, and when it might not be the best choice.
What is Ensemble Learning?
Ensemble learning is a machine learning paradigm where multiple models (often called “weak learners”) are trained to solve the same problem and combined to get better results. The main idea is that a group of weak learners can come together to form a strong learner, thereby improving the accuracy and robustness of the predictions.
Main types of Ensemble Methods
- Bagging:
Involves training multiple models independently on different random subsets of the training data and then averaging their predictions. - Boosting:
Trains models sequentially, each new model focusing on the errors of its predecessor. Popular boosting algorithms include AdaBoost, Gradient Boosting Machines (GBM), and XGBoost. - Stacking:
Involves training multiple models and then using another model (meta-learner) to combine their predictions.
How to Use Ensemble Learning
Implementing ensemble learning can be straightforward, thanks to various libraries like Scikit-learn, XGBoost, and LightGBM. Here’s a step-by-step guide using a simple example with Scikit-learn:
- Data Preparation:
Load and preprocess your data (e.g., handling missing values, encoding categorical variables). - Model Selection:
Choose the base models for your ensemble (e.g., Decision Trees, Logistic Regression, SVM). - Implement Ensemble Method:
Use an ensemble method like Bagging, Boosting, or Stacking. For instance, using Bagging in Scikit-learn. - Evaluation:
Evaluate the ensemble model using appropriate metrics (e.g., accuracy, F1-score, ROC-AUC).
When to Use Ensemble Learning
Ensemble learning is particularly useful in the following scenarios:
- Improving Accuracy:
When individual models do not provide satisfactory accuracy, combining them can lead to improved performance. - Reducing Overfitting:
Ensemble methods like Bagging can help reduce overfitting by averaging out biases and variances from different models. - Complex Problems:
For problems with complex data patterns, ensemble methods can capture various aspects of the data by combining multiple models.
Advantages of Ensemble Learning
- Improved Accuracy:
Combining multiple models often leads to better predictive performance than individual models. - Robustness:
Ensemble methods are less sensitive to the peculiarities of individual models, making them more robust. - Versatility:
They can be applied to various types of problems, including classification, regression, and anomaly detection.
Disadvantages of Ensemble Learning
- Computational Cost:
Training multiple models increases computational and memory requirements. - Complexity:
Implementing and tuning ensemble methods can be more complex and time-consuming. - Lack of Interpretability:
Understanding and interpreting the final model can be challenging, particularly in stacked or highly complex ensembles.
1. Bagging
Bagging, or Bootstrap Aggregating, is an ensemble learning technique designed to improve the stability and accuracy of machine learning algorithms. It works by generating multiple versions of a predictor and using these to get an aggregated predictor. The key idea behind Bagging is to reduce variance and prevent overfitting.
Process of Bagging
- Prepare Dataset:
– Start with the original training dataset. - Create Bootstrapped Samples:
– Randomly sample (with replacement) multiple subsets from the original dataset. - Train Base Models
– Train a separate instance of the same model (e.g., decision tree) on each bootstrapped sample. - Make Predictions
– Use each trained model to make predictions on new/unseen data. - Aggregate Predictions
– For regression: Average the predictions from all models.
– For classification: Use majority voting to determine the final class label. - Final Output
– Return the aggregated prediction as the final result.

2. Boosting
Boosting is an ensemble technique that combines multiple weak learners, typically simple models like decision stumps, to create a strong predictive model. Unlike other ensemble methods like bagging, where models are built independently, boosting builds models sequentially. Each new model in the sequence focuses on correcting the errors made by its predecessor, thereby improving overall performance.
Process of Boosting
The boosting process involves several key steps, iteratively applied to build a robust model:
1. Initialization:
– Assign equal weights to all training instances initially.
2. Training Weak Learners:
– Train a weak learner (e.g., a decision stump) on the weighted dataset.
– Evaluate the weak learner’s performance and calculate its error rate.
3. Weight Adjustment:
– Increase the weights of the instances that were misclassified by the weak learner.
– Decrease the weights of the correctly classified instances.
– This adjustment ensures that subsequent learners focus more on the hard-to-classify instances.
4. Model Combination:
– Combine the weak learners’ predictions, typically through a weighted sum or majority vote.
– The final prediction is determined by aggregating the outputs of all the weak learners.
5. Iteration:
– Repeat the process for a predefined number of iterations or until a stopping criterion is met.
– Each iteration adds a new weak learner that corrects the mistakes of the ensemble formed by the previous learners.

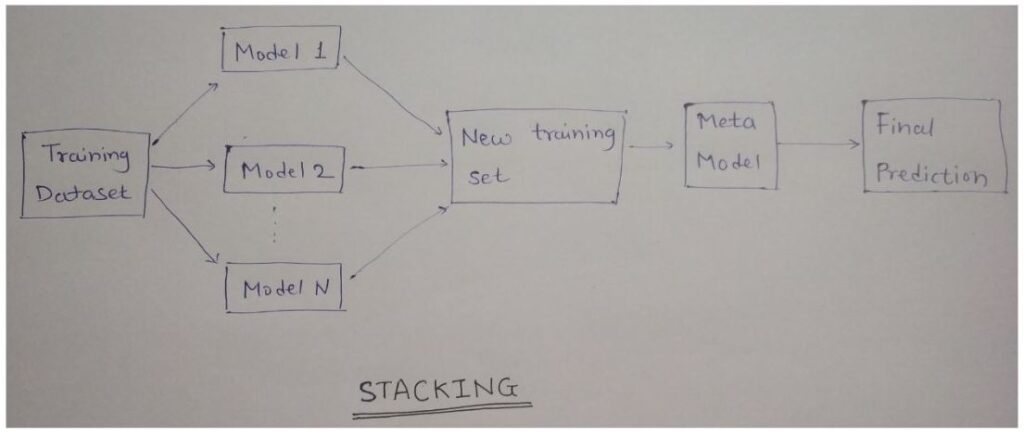
3. Stacking
Stacking, or stacked generalization, is an ensemble learning technique that combines multiple machine learning models to produce a superior predictive model. Unlike other ensemble methods like bagging and boosting that work on a homogeneous set of models, stacking leverages a diverse array of models, often referred to as base models or level-0 models. The predictions from these base models are then used as input features for a meta-model, also known as the level-1 model, which makes the final prediction.
Process of Stacking
1. Divide Data into Folds:
– The training dataset is divided into several folds (typically K-fold cross-validation is used).
2. Train Base Models:
– Each base model is trained on a subset of the data (K-1 folds) and validated on the remaining fold. This process is repeated K times for each base model, ensuring that each fold serves as the validation set once.
3. Generate Meta-Features:
– The predictions from the base models during the K-fold cross-validation are collected to form a new dataset, often referred to as meta-features.
4. Train Meta-Model:
– The meta-features, along with the true labels from the validation sets, are used to train the meta-model.
5. Make Final Predictions:
– During the prediction phase, the base models make predictions on the test set. These predictions are used as input to the meta-model, which generates the final predictions.
Conclusion
Ensemble learning is a powerful technique in the machine learning toolkit, offering improved accuracy and robustness by combining the strengths of multiple models. However, it’s essential to consider the trade-offs in computational cost and interpretability. By understanding when and how to use ensemble methods effectively, you can harness their full potential to solve complex machine learning problems.